
ISSN 2308-9113
ISSN 2308-9113 |
| О журнале | Редколлегия | Редсовет | Архив номеров | Поиск | Авторам | Рецензентам | English |
Применение метода Менделевской рандомизации при перепрофилировании лекарственных средств
Автор для корреспонденции: Плотников Денис Юрьевич; e-mail: denis.plotnikov@kazangmu.ru. Финансирование. Исследование не имело спонсорской поддержки. Конфликт интересов. Авторы заявляют об отсутствии конфликта интересов. Аннотация Разработка новых лекарственных средств является длительным и дорогостоящим процессом, поэтому применение уже зарегистрированных препаратов по новым показаниям (перепрофилирование) является перспективным направлением развития фармацевтической отрасли. Среди подходов к перепрофилированию лекарственных средств выделяют экспериментальные и вычислительные. В настоящее время, в связи с доступностью больших массивов данных, активно развиваются вычислительные методы, в том числе основанные на использовании искусственного интеллекта. Широкое применение генетических данных в разработке и перепрофилировании лекарственных средств привело к развитию такой области наук, как фармакогенетика. Доступность данных полногеномных анализов ассоциаций и транскриптомных данных позволяют применять метод Менделевской рандомизации для определения возможностей перепрофилирования лекарственных средств. В статье дается краткая характеристика метода Менделевской рандомизации и приводятся примеры ее применения для оценки эффекта лекарственных препаратов на различные заболевания. Ключевые слова перепрофилирование, лекарственные препараты, фармакогенетика, Менделевская рандомизация doi: 10.29234/2308-9113-2023-11-2-29-41 Для цитирования: Плотников Д. Ю., Колесникова Е. М., Халилов В. Р. Применение метода Менделевской рандомизации при перепрофилировании лекарственных средств. Медицина 2023; 11(2): 29-41 Введение Процесс разработки лекарств – это сложная и трудоемкая задача, требующая обширных исследований и разработок. Разработка нового лекарства с нуля может занять до 10-15 лет, стоить миллиарды долларов и иметь высокий процент неудач. [1]. Несмотря на значительные инвестиции и тщательные клинические испытания, лишь небольшой процент лекарств попадает на рынок. Частые неудачи могут быть объяснены различными факторами, такими как проблемы безопасности, недостаточная эффективность или неожиданные побочные эффекты [2]. Поскольку в случае ошибочного предположения о мишени (ложноположительный результат) и ее роли в патогенезе, прохождение кандидатом фаз клинических испытаний будет невозможно чаще всего из-за возникающих фатальных побочных эффектов. Следовательно, для повышения производительности фармацевтической отрасли необходимы более точные подходы. Так, в качестве примера можно рассмотреть метод, основанный на знании структуры мишени лекарственного препарата (target-based), благодаря которому противолейкозный цитостатический препарат иматиниб был создан и запатентован в кратчайшие сроки [3]. Поэтому возможность использования подходов способных сократить время и затраты производства на основе использования опубликованных данных является перспективным направлением развития фармацевтической отрасли. Цель работы Целью работы является анализ возможности применения метода Менделевской рандомизации при перепрофилировании лекарственных средств. Результаты и обсуждение Стратегии перепрофилирования лекарственных средств В последние годы в качестве альтернативы традиционной разработке лекарственных средств появилась технология повторного применения лекарств. Перепрофилирование лекарств подразумевает поиск новых применений для существующих препаратов, которые уже были одобрены для других показаний. Этот подход имеет ряд преимуществ, включая снижение затрат на разработку, сокращение сроков разработки и более высокий процент успеха. Существует два принципиальных подхода к перепрофилированию лекарств – это экспериментальный и вычислительный [4]. Среди вычислительных методов перспективными и широко применяемыми являются молекулярный докинг и машинное обучение [5]. Моделирование специфического взаимодействия "лиганд (молекула лекарства) – рецептор (белок)" позволяет предсказать наиболее энергетически выгодную для образования устойчивого комплекса конформацию и ориентацию одной молекулы в сайте связывания другой. Это позволяет провести полноценное теоретическое исследование, в результате определяя не только аффинность, энергию связывания, но и активность лекарственного соединения, тем самым выясняя механизм взаимодействия. Однако существуют некоторые ограничения в использовании молекулярного докинга при перепрофилировании лекарств, например, необходимость в известной трехмерной (3D) структуры химических лигандов и белковых мишеней. Ошибки в определенной структуре белка и неполное моделирование атомных и молекулярных взаимодействий повышает частоту ложноположительных результатов [6]. Более того, метод требует значительных вычислительных ресурсов, что приводит к увеличению времени выполнения. Метод машинного обучения рассматривает перепрофилирование лекарств как проблему контролируемого обучения, где алгоритмы, применяемые к биологическим данным, связывают их с базой препаратов, используемых в терапии конкретных заболеваний [7]. Машинное обучение кажется более рациональным, чем молекулярный докинг, поскольку позволяет изучить большее число перспективных кандидатов для дальнейшего экспериментального скрининга. К тому же в зависимости от подхода к перепрофилированию существует вариантность анализа, так исследователь может использовать информацию, основанную как на знании химических и фармакологических особенностей, так и на симптоматике или патологии [6]. Каждый подход содержит уникальные задачи информатики, часто требующие включения элементов как из методов, основанных на лекарствах, так и на заболеваниях. Такие возможности отлично работают в условиях недостатка информации по одному из критериев, например, подходы, основанные на заболевании, могут быть предпочтительнее при недостаточных знаниях фармакокинетики и фармакодинамики лекарственных средств. Влияние генетических факторов на действие лекарственных средств Согласно проведенным исследованиям, в среднем последовательности ДНК любых двух людей совпадают на 99,9%, а вариация в 0,1% хоть и кажется на первый взгляд незначительной, однако именно она объясняет фенотипические различия [8]. Гены, как функциональные единицы ДНК, заключают информацию, которая направляет основную клеточную деятельность целого организма. Исходя из сказанного выше понятно, что при назначении лекарственных препаратов для повышения эффективности и безопасности назначенной терапии необходимо учитывать генетические особенности пациентов. Для этого была создана отдельная дисциплина – фармакогеномика, направленная на выявление связи между наследуемым признаком и лекарственной реакцией [9]. Однако существует синонимичный термин: фармакогенетика. Принципиальная разница между ними заключается в том, что фармакогеномика нацелена на изучение влияний целого генома на лекарственные реакции, а не отдельных генов [10]. Известно, что лекарственная молекула оказывает влияние на организм за счет связывания с рецептором, который представляет из себя белок, состоящий из определенного специфичного для него количества доменов [11]. Наличие той или иной конформации белковой молекулы, ее роль и функция генетически детерминированы, а значит, реакции на лекарственный препарат зависят от различий как в фармакодинамике, так и в фармакокинетике [12]. Вариации генов, кодирующих белковые молекулы, например белки-переносчики, осуществляющие процесс облегченной диффузии, белки-ферменты, участвующие в биотрансформации и белки-мишени, которые непосредственно запускают каскадные сигналы в клетке – определяют индивидуальный ответ и приводят к существенным различиям как в профиле параметров ADME (всасывания, распределения, метаболизма и выведения), так и к изменениям количества белков-рецепторов, тем самым модулируя их молекулярную структуру и затрудняя связывание [13]. На сегодняшний день известны гены ответственные за действие препаратов из различных фармакологических групп, причем идентифицированы ферменты, полиморфизмы генов которых модулируют действие не одного, а многих лекарственных средств [12]. Согласно исследованиям, введение генотипирования перед назначением антикоагулянтов непрямого действия [14], противотуберкулезных, противоэпилептических и противоопухолевых средств могло бы предоставить огромное преимущество в минимизации побочных эффектов и контроле биодоступности, поскольку генетические различия могут быть фатальными у пациентов с наследственной вариабельностью белков, которые участвуют в множестве биохимических процессов. Концепция фармакогенетики первично возникла при клинических наблюдениях, только потом были идентифицированы ферменты, метаболизирующие лекарства, а затем гены, кодирующие белки, и вариации последовательности ДНК в генах, которые были связаны с наследуемым признаком. Значительная часть впервые идентифицированных фармакогенетических признаков были моногенными (включали только один ген), и большинство из них обусловлены генетическими полиморфизмами; то есть, аллель или аллели, ответственные за вариацию, были относительно распространенными [12]. Однако эффект от приема лекарственных средств представляет собой сложный фенотип, определяемый действием многих факторов, что конечно же стоит учитывать [12]. В настоящее время в перепрофилировании лекарственных средств широко применяются "омиксные" данные и технологии, позволяющие использовать знания человеческого генома, протеома, метаболома [15,16]. Менделевская рандомизация Менделевская рандомизация (МР) – это статистический метод, который может быть использован для исследования причинно-следственной связи между конкретным воздействием и интересующим исходом путем использования генетических вариантов в качестве инструментальных переменных [17]. Этот подход может быть использован при перепрофилировании лекарств для выявления новых показаний для уже одобренных препаратов или прогнозирования потенциальных неблагоприятных лекарственных событий [18]. Полногеномные исследования ассоциаций (GWAS) изменили наше понимание генетической основы комплексных заболеваний и фенотипических признаков путем выявления генетических вариантов, связанных с этими признаками [19]. Однако важность GWAS выходит за рамки только обнаружения генетических вариантов, связанных с тем или иным признаком. Результаты GWAS, чаще в виде сводной статистики можно эффективно использовать для определения наличия и для оценки причинно-следственных связей между различными факторами риска и интересующим исследователя признаком. Одним из широко применяемых методов вывода причинно-следственных связей на основе GWAS является МР [20,21]. МР – это статистический метод, в котором генетические варианты служат в качестве инструментальных переменных и позволяют оценить эффект исследуемого фактора риска (биомаркера) на заболевание [22]. МР помогает установить и оценить причинно-следственную связь, используя знание закона Менделя о независимом распределении аллелей во время мейоза, что позволяет провести аналогию между МР и рандомизированным контролируемым исследованием [23]. Валидность инструментальной переменной обеспечивается выполнением трех условий (рис. 1). Во-первых, это значимая ассоциация инструмента с фактором риска или биомаркером. во-вторых, отсутствие ассоциации с конфаундерами (вмешивающимися факторами); в-третьих, ассоциация c заболеванием (исходом) идет только через фактор риска. Доступность данных сводной статистики крупных полногеномных исследований ассоциаций делает поиск инструментов, отвечающих первому условию, несложным процессом. Уровень значимости ассоциации инструмента с биомаркером, как правило меньше 5х10-08. Выполнение второго и третьего условий невозможно протестировать; исследователи выполняют серию анализов чувствительности, специально разработанных для получения достоверной оценки в тех случаях, когда один или несколько инструментальных переменных на являются валидными [24,25]. Рис. 1. Графическая модель Менделевской рандомизации 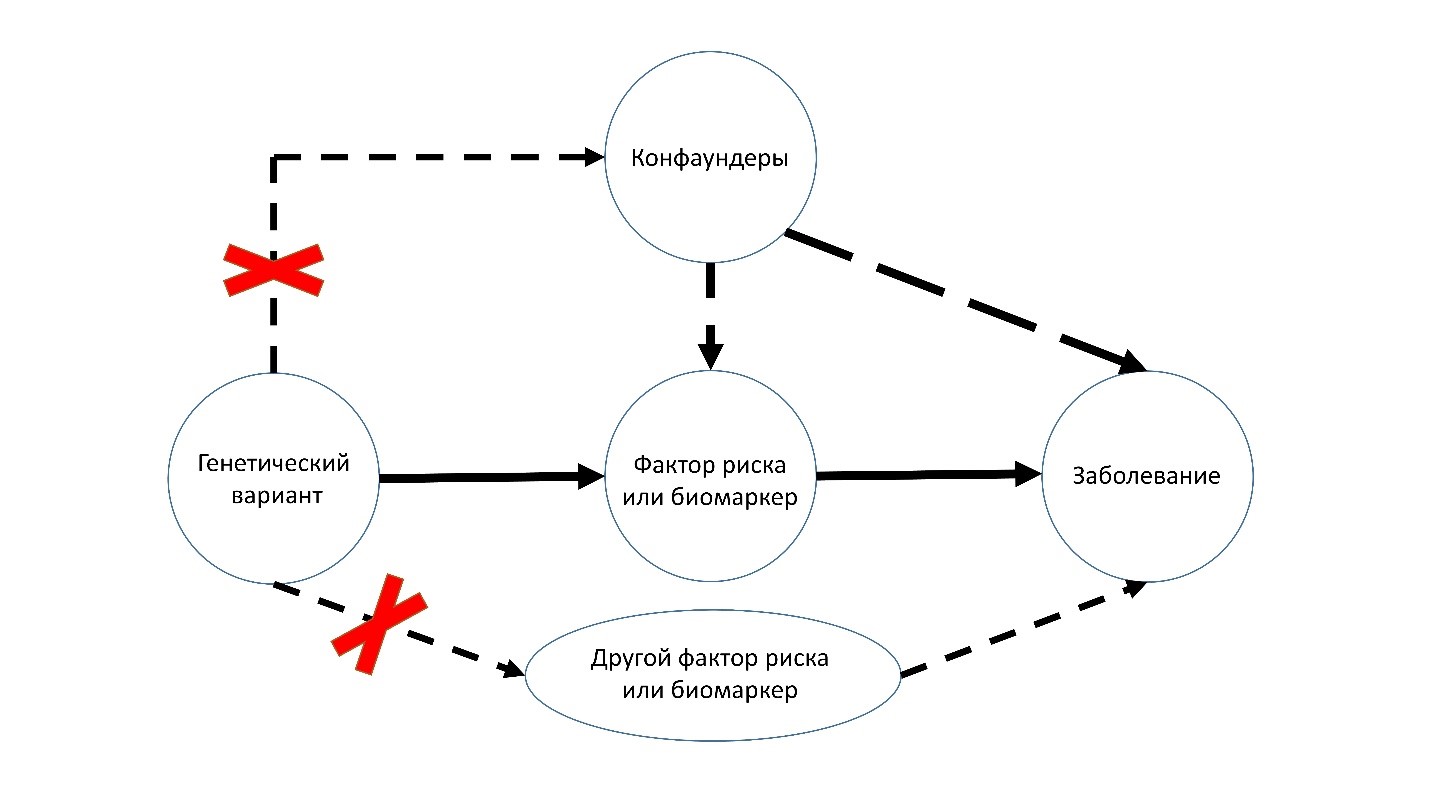 МР имеет ряд преимуществ перед традиционными наблюдательными исследованиями. МР менее подвержена влиянию конфаундинга и обратной причинно-следственной связи [26]. Также, применение МР обосновано в тех случаях, когда проведение рандомизированных контролируемых исследований невозможно по этическим или финансовым причинам. Наконец, ее можно использовать для выявления потенциальных мишеней лекарственных средств и возможности перепрофилирования, также для оценки риска возникновения побочных эффектов. Рис. 2. Сравнение цис-МР с рандомизированным контролируемым исследованием. 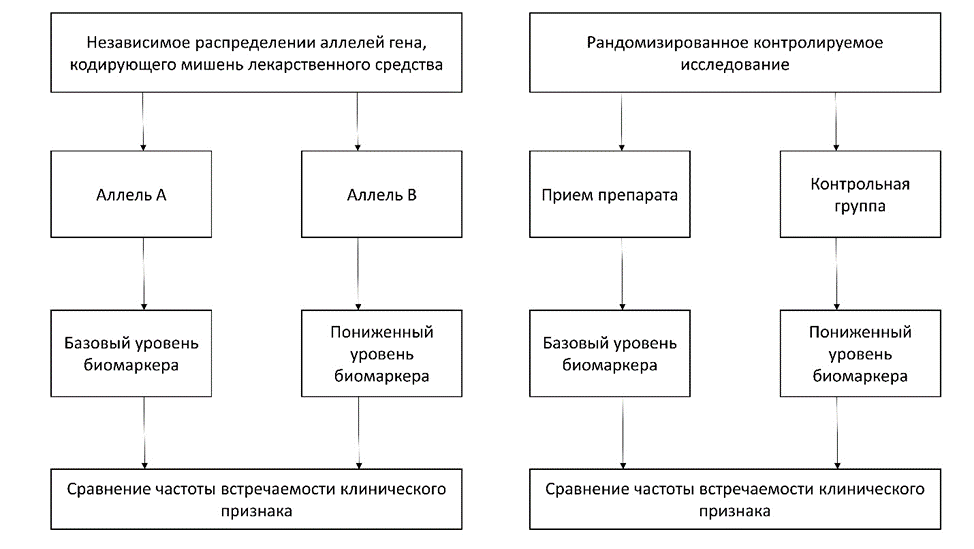 Примеры применения МР При проведении МР для оценки эффекта мишени лекарственного препарата, полиморфизмы, связанные с функцией или экспрессией белка-мишени, могут быть использованы в качестве инструментальных переменных [18,27] (рис. 2). Такие варианты, как правило, находятся в регионе гена, кодирующего лекарственную мишень, и называются цис-вариантами, а метод получил название цис-МР [28]. Среди примеров исследований, в которых применялись цис-варианты стоит отметить изучение рецептора интерлейкина-6 как возможной мишени при профилактике ишемической болезни сердца [29]. Авторы использовали однонуклеотидные полиморфизмы (SNPs) в гене IL6R для оценки вероятной эффективности и безопасности ингибирования IL6R для первичной профилактики ишемической болезни сердца. При сравнении результатов генетических исследований с эффектом приема тоцилизумаба (блокатора интерлейкина-6), о которых сообщалось в рандомизированных испытаниях у пациентов с ревматоидным артритом, были получены сопоставимые результаты. Однако в некоторых случаях один ген может не представлять эффект цис-действующего варианта на интересующий признак, что требует применения комбинации генетических полиморфизмов, расположенных в регионах разных генов (полигенная МР) [30]. Например, в ряде исследований с применением метода МР было подтверждено наличие причинно-следственной связи витамина D с различными заболеваниями, что подтверждает терапевтическую значимость приема витамина D [31-33]. Gao и соавт. [31] использовали 137 однонуклеотидных полиморфизмов, значимо ассоциированных с уровнем 25-гидроксикальциферола в крови в качестве инструментальных переменных для оценки влияния дефицита витамина D на риск развития сердечной недостаточности. Авторы показали значимое снижение риска развития сердечной недостаточности при повышении уровня 25-гидроксикальциферола в крови (ОШ = 0,81, р = 0,006), что подтверждается результатами экспериментальных исследований [34]. Значимая ассоциация витамина D с деменцией была обнаружена в работе Navale и соавторов [32]. Авторы провели как срезовое исследование, использовав данные 427690 участников Биобанка Великобритании, так и МР. Для этого авторы создали полигенный индекс риска на основе генотипа 35 полиморфизмов, выявленных в крупномасштабном полногеномном исследовании ассоциаций витамина D [35]. Полученные результаты позволили сделать вывод, что повышение уровня 25-гидроксикальциферола до 50 нМоль/л способно предотвратить до 17% случаев деменции (95% ДИ 7,22 – 30,58). Интересное исследование было проведено Gaziano и соавторами в 2021 году [36]. Авторы провели серию анализов методом МР для выявления терапевтических мишеней, имеющих отношение к COVID-19. Вначале были определены 1263 белковые мишени, на которые воздействуют лекарственные препараты, получившие одобрение регуляторных органов. Для этого использовались данные о механизме действия лекарственных препаратов, содержащиеся в базе ChEMBL [37], что привело к выявлению 1623 протеинов. Инструментальные переменные были выбраны на основе изучения транскриптомных и протеомных данных и сводных статистических данных крупного полногеномного исследования COVID-19, проведенного на выборке из 7554 пациентов с коронавирусной инфекцией и более миллиона человек в контрольной группе [38,39]. В результате, полученные данные позволили сделать вывод, что белки IFNAR2 и ACE2 являются потенциальными мишенями при ранней терапии COVID-19. Khankari и соавторы в 2022 году опубликовали результаты своего исследования по изучению возможности применения гиполипидемических препаратов для профилактики развития сахарного диабета 2 типа [40]. В своей работе авторы использовали эффект генетически опосредованной экспрессии генов (метод S-PrediXcan) [41] в 49 различных тканях человеческого организма на уровень липидов крови и выявили роль этил-эйкозапентоеновой кислоты. Снижение уровня триглицеридов при приеме этил-эйкозапентоеновой кислоты было ассоциировано со снижением риска развития сахарного диабета 2 типа на 53%. Несмотря на столь обнадеживающий результат, авторы подчеркивают необходимость проведения экспериментов с использованием лабораторных животных перед началом рандомизированных контролируемых исследований. Ограничения метода МР Как и любой метод, МР имеет свои ограничения. В первую очередь, важно понимать, что генетически опосредованный эффект биомаркера или мишени лекарственного препарата отличается от того эффекта, который оценивается в клинических испытаниях. В первом случае, мы говорим о влиянии, которое оказывается на протяжении длительного периода времени, тогда как во втором случае речь идет об одномоментном эффекте. Кроме того, наличие плейотропии может привести к получению смещенной оценки, поэтому необходимо проводить серию анализов чувствительности. Также необходимым условием для проведения корректный выбор инструментальных переменных, то есть при выборе генетических вариантов в регионе гена, кодирующего протеин, лекарственные препараты должны взаимодействовать с этим протеином. Заключение В последнее время МР рандомизация стала широко применяться не только в эпидемиологических исследованиях, но и в разработке новых или оценке возможности перепрофилирования уже зарегистрированных лекарственных средств. Сейчас, в век цифровых технологий и использования больших массивов данных, в том числе генетических, перспективным для развития персонифицированного лечения является междисциплинарный подход, комбинирующий омиксные методы, МР, машинное обучение. Список литературы 1. Hughes J.P., Rees S., Kalindjian S.B., et al. Principles of early drug discovery. Br J Pharmacol 2011; 162: 1239-1249. 2. Saberian N., Peyvandipour A., Donato M., et al. A new computational drug repurposing method using established disease-drug pair knowledge. Bioinformatics 2019; 35: 3672-3678. 3. Johnson J.R., Bross P., Cohen M., et al. Approval summary: imatinib mesylate capsules for treatment of adult patients with newly diagnosed philadelphia chromosome-positive chronic myelogenous leukemia in chronic phase. Clin Cancer Res 2003; 9: 1972-1979. 4. Максимов А.С., Дергачёва Ж.М. Стратегия перепрофилирования в поиске новых лекарственных средств. Вестник фармации 2020; (4): 85-99. 5. Lotfi Shahreza M., Ghadiri N., Mousavi S.R., et al. A review of network-based approaches to drug repositioning. Brief Bioinform 2018; 19: 878-892. 6. Dudley J.T., Deshpande T., Butte A.J. Exploiting drug-disease relationships for computational drug repositioning. Brief Bioinform 2011; 12: 303-311. 7. Ding H., Takigawa I., Mamitsuka H., et al. Similarity-based machine learning methods for predicting drug-target interactions: a brief review. Brief Bioinform 2014; 15: 734-747. 8. Mroziewicz M., Tyndale R.F. Pharmacogenetics: a tool for identifying genetic factors in drug dependence and response to treatment. Addict Sci Clin Pract 2010; 5: 17-29. 9. Karczewski K.J., Daneshjou R., Altman R.B. Chapter 7: Pharmacogenomics. PLoS Comput Biol 2012; 8: e1002817. 10. Relling M.V., Evans W.E. Pharmacogenomics in the clinic. Nature 2015; 526: 343-350. 11. Гилман А.Г., Клиническая фармакология по Гудману и Гилману. Пер. с англ. Под ред. Р.Р. Алиповой. В 4 томах, Москва, 2006. 12. Weinshilboum R. Inheritance and drug response. N Engl J Med 2003; 348: 529-537. 13. Goodman L.S., Brunton L.L., Chabner B., et al. (eds). Goodman & Gilman’s pharmacological basis of therapeutics. 12th ed. New York: McGraw-Hill, 2011. 14. Wadelius M., Pirmohamed M. Pharmacogenetics of warfarin: current status and future challenges. Pharmacogenomics J 2007; 7: 99-111. 15. Pantziarka P., Meheus L. Omics-driven drug repurposing as a source of innovative therapies in rare cancers. Expert Opinion on Orphan Drugs 2018; 6: 513-517. 16. Zhang M., Luo H., Xi Z., et al. Drug Repositioning for Diabetes Based on ‘Omics’ Data Mining. PLoS ONE 2015; 10: e0126082. 17. Reay W.R., Cairns M.J. Advancing the use of genome-wide association studies for drug repurposing. Nat Rev Genet 2021; 22: 658-671. 18. Walker V.M., Davey Smith G., Davies N.M., et al. Mendelian randomization: a novel approach for the prediction of adverse drug events and drug repurposing opportunities. International Journal of Epidemiology 2017; 46: 2078-2089. 19. Loos R.J.F. 15 years of genome-wide association studies and no signs of slowing down. Nat Commun 2020; 11: 5900. 20. Lawlor D.A., Harbord R.M., Sterne J.A.C., et al. Mendelian randomization: Using genes as instruments for making causal inferences in epidemiology. Statist Med 2008; 27: 1133-1163. 21. Davey Smith G., Ebrahim S. ‘Mendelian randomization’: can genetic epidemiology contribute to understanding environmental determinants of disease? International Journal of Epidemiology 2003; 32: 1-22. 22. Burgess S., Davey Smith G., Davies N.M., et al. Guidelines for performing Mendelian randomization investigations. Wellcome Open Res 2020; 4: 186. 23. Thanassoulis G., O’Donnell C.J. Mendelian Randomization: Nature’s Randomized Trial in the Post-Genome Era. JAMA 2009; 301: 2386. 24. Bowden J., Davey Smith G., Burgess S. Mendelian randomization with invalid instruments: effect estimation and bias detection through Egger regression. International Journal of Epidemiology 2015; 44: 512-525. 25. Hartwig F.P., Davey Smith G., Bowden J. Robust inference in summary data Mendelian randomization via the zero modal pleiotropy assumption. International Journal of Epidemiology 2017; 46: 1985-1998. 26. Davey Smith G., Hemani G. Mendelian randomization: genetic anchors for causal inference in epidemiological studies. Human Molecular Genetics 2014; 23: R89-R98. 27. Schmidt A.F., Finan C., Gordillo-Marañón M., et al. Genetic drug target validation using Mendelian randomisation. Nat Commun 2020; 11: 3255. 28. Gkatzionis A., Burgess S., Newcombe P.J. Statistical Methods for cis-Mendelian Randomization with Two-sample Summary-level Data. arXiv:2101.04081v2, doi: 10.48550/arXiv.2101.04081 29. Interleukin-6 Receptor Mendelian Randomisation Analysis (IL6R MR) Consortium; Swerdlow D.I., Holmes M.V., et al. The interleukin-6 receptor as a target for prevention of coronary heart disease: a mendelian randomisation analysis. Lancet 2012; 379: 1214-1224. 30. Burgess S., Butterworth A., Thompson S.G. Mendelian Randomization Analysis with Multiple Genetic Variants Using Summarized Data. Genet Epidemiol 2013; 37: 658-665. 31. Gao N., Li X., Kong M., et al. Associations Between Vitamin D Levels and Risk of Heart Failure: A Bidirectional Mendelian Randomization Study. Front Nutr 2022; 9: 910949. 32. Navale S.S., Mulugeta A., Zhou A., et al. Vitamin D and brain health: an observational and Mendelian randomization study. The American Journal of Clinical Nutrition 2022; 116: 531-540. 33. Sutherland J.P., Zhou A., Hyppönen E. Vitamin D Deficiency Increases Mortality Risk in the UK Biobank: A Nonlinear Mendelian Randomization Study. Ann Intern Med 2022; 175: 1552-1559. 34. Gardner D.G., Chen S., Glenn D.J. Vitamin D and the heart. American Journal of Physiology-Regulatory, Integrative and Comparative Physiology 2013; 305: R969-R977. 35. Revez J.A., Lin T., Qiao Z., et al. Genome-wide association study identifies 143 loci associated with 25 hydroxyvitamin D concentration. Nat Commun 2020; 11: 1647. 36. Gaziano L., Giambartolomei C., Pereira A.C., et al. Actionable druggable genome-wide Mendelian randomization identifies repurposing opportunities for COVID-19. Nat Med 2021; 27: 668-676. 37. Mendez D., Gaulton A., Bento A.P., et al. ChEMBL: towards direct deposition of bioassay data. Nucleic Acids Research 2019; 47: D930-D940. 38. Gaziano J.M., Concato J., Brophy M., et al. Million Veteran Program: A mega-biobank to study genetic influences on health and disease. Journal of Clinical Epidemiology 2016; 70: 214-223. 39. The COVID-19 Host Genetics Initiative. The COVID-19 Host Genetics Initiative, a global initiative to elucidate the role of host genetic factors in susceptibility and severity of the SARS-CoV-2 virus pandemic. Eur J Hum Genet 2020; 28: 715-718. 40. Khankari N.K., Keaton J.M., Walker V.M., et al. Using Mendelian randomisation to identify opportunities for type 2 diabetes prevention by repurposing medications used for lipid management. eBioMedicine 2022; 80: 104038. 41. Barbeira A.N., Dickinson S.P., Bonazzola R., et al. Exploring the phenotypic consequences of tissue specific gene expression variation inferred from GWAS summary statistics. Nat Commun 2018; 9: 1825.
Corresponding Author: Denis Plotnikov; e-mail: denis.plotnikov@kazangmu.ru. Conflict of interest. None declared. Funding. The study had no sponsorship. Abstract The development of new drugs is a time consuming and costly process, so the use of approved drugs for new indications (repurposing) is a promising area of development for the pharmaceutical industry. There are two main approaches for drug development: experimental and computational. Currently, due to the availability of large data sets, computational methods, including those based on the use of artificial intelligence, are being actively developed. The widespread use of genetic data in drug development and repurposing has led to the development of such a field of science as pharmacogenetics. The availability of genome-wide association analyses and transcriptome data allow the Mendelian randomization method to be applied to determine the potential for drug repurposing. This article briefly describes the Mendelian randomization method and provides examples of its application to assess the effect of drugs on various diseases. Key words repurposing, drugs, pharmacogenetics, Mendelian randomization References 1. Hughes J.P., Rees S., Kalindjian S.B., et al. Principles of early drug discovery. Br J Pharmacol 2011; 162: 1239-1249. 2. Saberian N., Peyvandipour A., Donato M., et al. A new computational drug repurposing method using established disease-drug pair knowledge. Bioinformatics 2019; 35: 3672-3678. 3. Johnson J.R., Bross P., Cohen M., et al. Approval summary: imatinib mesylate capsules for treatment of adult patients with newly diagnosed philadelphia chromosome-positive chronic myelogenous leukemia in chronic phase. Clin Cancer Res 2003; 9: 1972-1979. 4. Maksimov A.S., Dergachyova Zh.M. Strategiya pereprofilirovaniya v poiske novyh lekarstvennyh sredstv. [Repurposing strategy in the search for new drugs.] Vestnik farmacii [Bulletin of Pharmacy] 2020; (4): 85-99. (In Russ.) 5. Lotfi Shahreza M., Ghadiri N., Mousavi S.R., et al. A review of network-based approaches to drug repositioning. Brief Bioinform 2018; 19: 878-892. 6. Dudley J.T., Deshpande T., Butte A.J. Exploiting drug-disease relationships for computational drug repositioning. Brief Bioinform 2011; 12: 303-311. 7. Ding H., Takigawa I., Mamitsuka H., et al. Similarity-based machine learning methods for predicting drug-target interactions: a brief review. Brief Bioinform 2014; 15: 734-747. 8. Mroziewicz M., Tyndale R.F. Pharmacogenetics: a tool for identifying genetic factors in drug dependence and response to treatment. Addict Sci Clin Pract 2010; 5: 17-29. 9. Karczewski K.J., Daneshjou R., Altman R.B. Chapter 7: Pharmacogenomics. PLoS Comput Biol 2012; 8: e1002817. 10. Relling M.V., Evans W.E. Pharmacogenomics in the clinic. Nature 2015; 526: 343-350. 11. Gilman A.G., Klinicheskaya farmakologiya po Gudmanu i Gilmanu. [Goodman & Gilman’s pharmacological basis of therapeutics]. Editor of translation in Russian R.R. Alipova. Moscow, 2006. (In Russ.) 12. Weinshilboum R. Inheritance and drug response. N Engl J Med 2003; 348: 529-537. 13. Goodman L.S., Brunton L.L., Chabner B., et al. (eds). Goodman & Gilman’s pharmacological basis of therapeutics. 12th ed. New York: McGraw-Hill, 2011. 14. Wadelius M., Pirmohamed M. Pharmacogenetics of warfarin: current status and future challenges. Pharmacogenomics J 2007; 7: 99-111. 15. Pantziarka P., Meheus L. Omics-driven drug repurposing as a source of innovative therapies in rare cancers. Expert Opinion on Orphan Drugs 2018; 6: 513-517. 16. Zhang M., Luo H., Xi Z., et al. Drug Repositioning for Diabetes Based on ‘Omics’ Data Mining. PLoS ONE 2015; 10: e0126082. 17. Reay W.R., Cairns M.J. Advancing the use of genome-wide association studies for drug repurposing. Nat Rev Genet 2021; 22: 658-671. 18. Walker V.M., Davey Smith G., Davies N.M., et al. Mendelian randomization: a novel approach for the prediction of adverse drug events and drug repurposing opportunities. International Journal of Epidemiology 2017; 46: 2078-2089. 19. Loos R.J.F. 15 years of genome-wide association studies and no signs of slowing down. Nat Commun 2020; 11: 5900. 20. Lawlor D.A., Harbord R.M., Sterne J.A.C., et al. Mendelian randomization: Using genes as instruments for making causal inferences in epidemiology. Statist Med 2008; 27: 1133-1163. 21. Davey Smith G., Ebrahim S. ‘Mendelian randomization’: can genetic epidemiology contribute to understanding environmental determinants of disease? International Journal of Epidemiology 2003; 32: 1-22. 22. Burgess S., Davey Smith G., Davies N.M., et al. Guidelines for performing Mendelian randomization investigations. Wellcome Open Res 2020; 4: 186. 23. Thanassoulis G., O’Donnell C.J. Mendelian Randomization: Nature’s Randomized Trial in the Post-Genome Era. JAMA 2009; 301: 2386. 24. Bowden J., Davey Smith G., Burgess S. Mendelian randomization with invalid instruments: effect estimation and bias detection through Egger regression. International Journal of Epidemiology 2015; 44: 512-525. 25. Hartwig F.P., Davey Smith G., Bowden J. Robust inference in summary data Mendelian randomization via the zero modal pleiotropy assumption. International Journal of Epidemiology 2017; 46: 1985-1998. 26. Davey Smith G., Hemani G. Mendelian randomization: genetic anchors for causal inference in epidemiological studies. Human Molecular Genetics 2014; 23: R89-R98. 27. Schmidt A.F., Finan C., Gordillo-Marañón M., et al. Genetic drug target validation using Mendelian randomisation. Nat Commun 2020; 11: 3255. 28. Gkatzionis A., Burgess S., Newcombe P.J. Statistical Methods for cis-Mendelian Randomization with Two-sample Summary-level Data. arXiv:2101.04081v2, doi: 10.48550/arXiv.2101.04081 29. Interleukin-6 Receptor Mendelian Randomisation Analysis (IL6R MR) Consortium; Swerdlow D.I., Holmes M.V., et al. The interleukin-6 receptor as a target for prevention of coronary heart disease: a mendelian randomisation analysis. Lancet 2012; 379: 1214-1224. 30. Burgess S., Butterworth A., Thompson S.G. Mendelian Randomization Analysis with Multiple Genetic Variants Using Summarized Data. Genet Epidemiol 2013; 37: 658-665. 31. Gao N., Li X., Kong M., et al. Associations Between Vitamin D Levels and Risk of Heart Failure: A Bidirectional Mendelian Randomization Study. Front Nutr 2022; 9: 910949. 32. Navale S.S., Mulugeta A., Zhou A., et al. Vitamin D and brain health: an observational and Mendelian randomization study. The American Journal of Clinical Nutrition 2022; 116: 531-540. 33. Sutherland J.P., Zhou A., Hyppönen E. Vitamin D Deficiency Increases Mortality Risk in the UK Biobank: A Nonlinear Mendelian Randomization Study. Ann Intern Med 2022; 175: 1552-1559. 34. Gardner D.G., Chen S., Glenn D.J. Vitamin D and the heart. American Journal of Physiology-Regulatory, Integrative and Comparative Physiology 2013; 305: R969-R977. 35. Revez J.A., Lin T., Qiao Z., et al. Genome-wide association study identifies 143 loci associated with 25 hydroxyvitamin D concentration. Nat Commun 2020; 11: 1647. 36. Gaziano L., Giambartolomei C., Pereira A.C., et al. Actionable druggable genome-wide Mendelian randomization identifies repurposing opportunities for COVID-19. Nat Med 2021; 27: 668-676. 37. Mendez D., Gaulton A., Bento A.P., et al. ChEMBL: towards direct deposition of bioassay data. Nucleic Acids Research 2019; 47: D930-D940. 38. Gaziano J.M., Concato J., Brophy M., et al. Million Veteran Program: A mega-biobank to study genetic influences on health and disease. Journal of Clinical Epidemiology 2016; 70: 214-223. 39. The COVID-19 Host Genetics Initiative. The COVID-19 Host Genetics Initiative, a global initiative to elucidate the role of host genetic factors in susceptibility and severity of the SARS-CoV-2 virus pandemic. Eur J Hum Genet 2020; 28: 715-718. 40. Khankari N.K., Keaton J.M., Walker V.M., et al. Using Mendelian randomisation to identify opportunities for type 2 diabetes prevention by repurposing medications used for lipid management. eBioMedicine 2022; 80: 104038. 41. Barbeira A.N., Dickinson S.P., Bonazzola R., et al. Exploring the phenotypic consequences of tissue specific gene expression variation inferred from GWAS summary statistics. Nat Commun 2018; 9: 1825. |
[ См. также ] Рубрики |
||||
|
|
|
Журнал «Медицина» © ООО "Инновационные социальные проекты"
|
